Lexington
-
Compteur de contenus
18 469 -
Inscription
-
Dernière visite
-
Jours gagnés
76
Tout ce qui a été posté par Lexington
-

Guerre civile culture, IDW, SJW & co
Lexington a répondu à un sujet de 0100011 dans Politique, droit et questions de société
Ils sont partout !
-
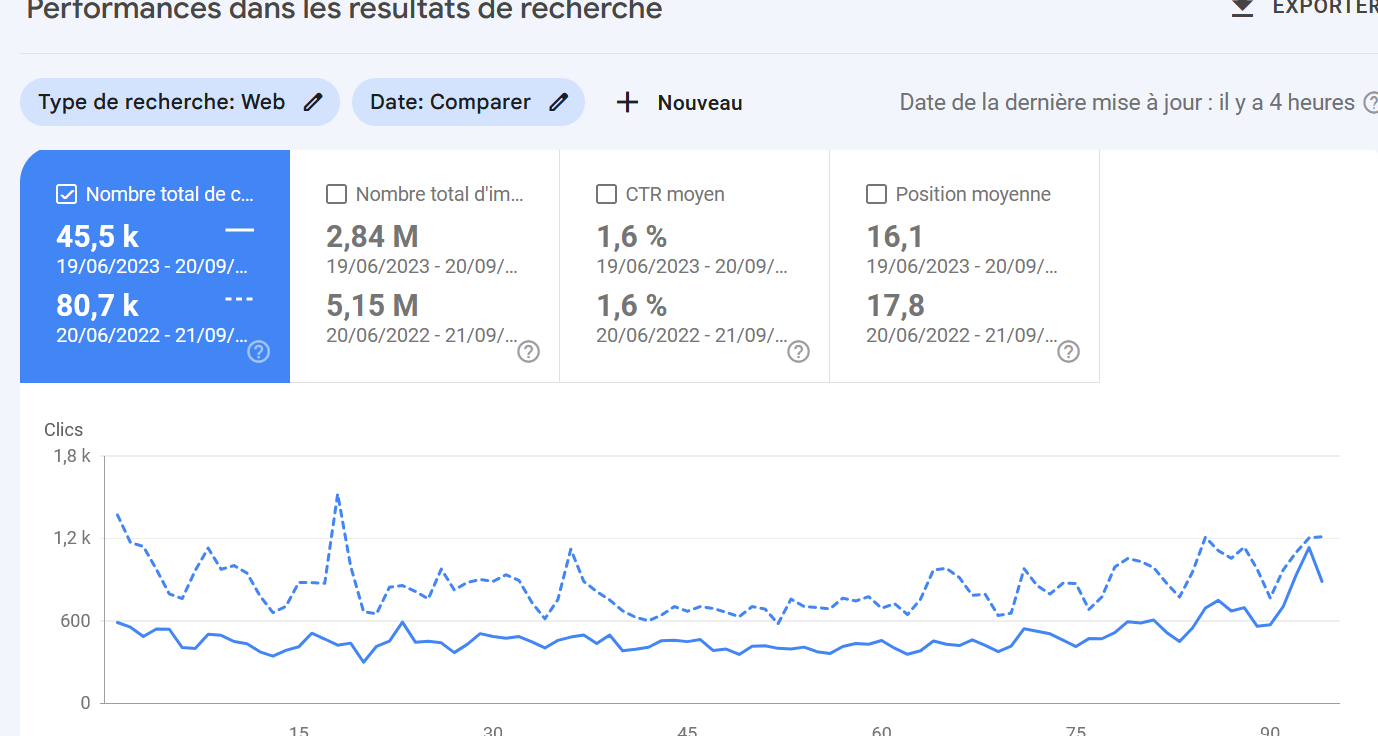
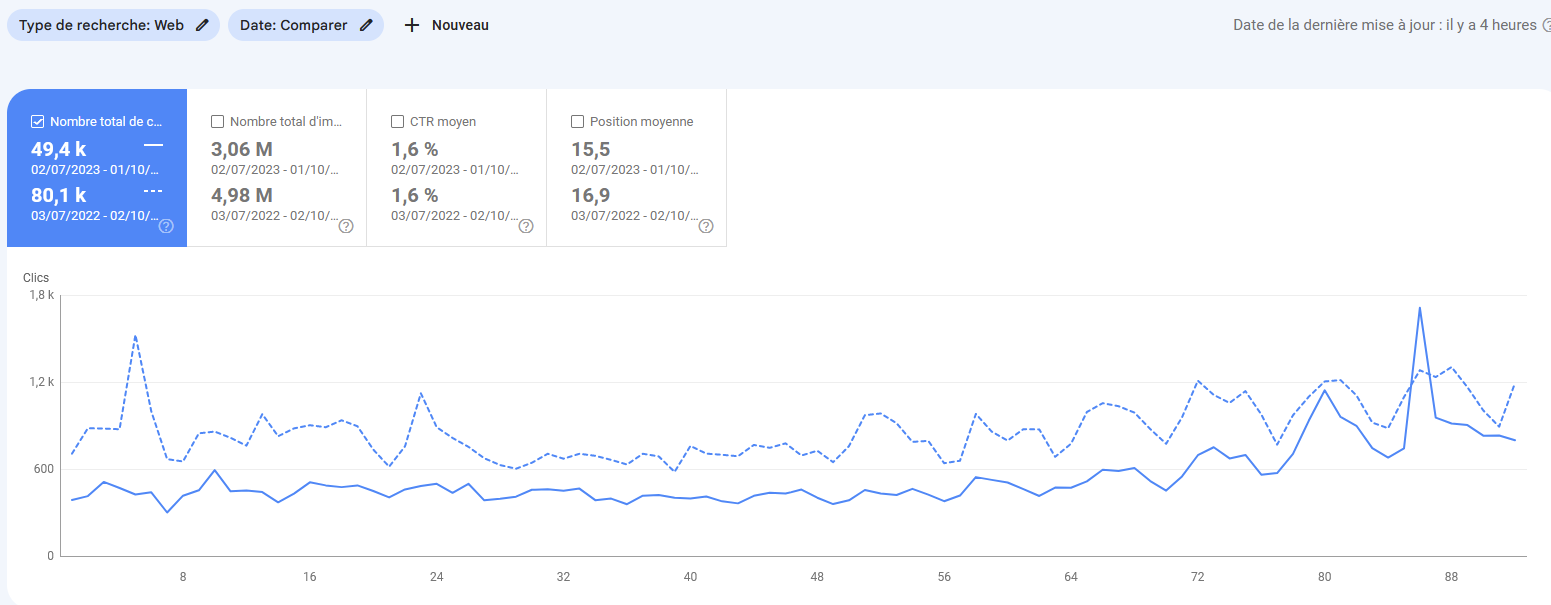
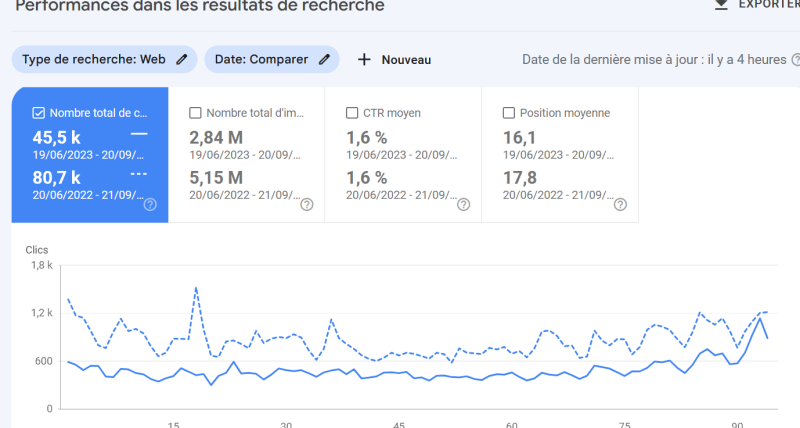
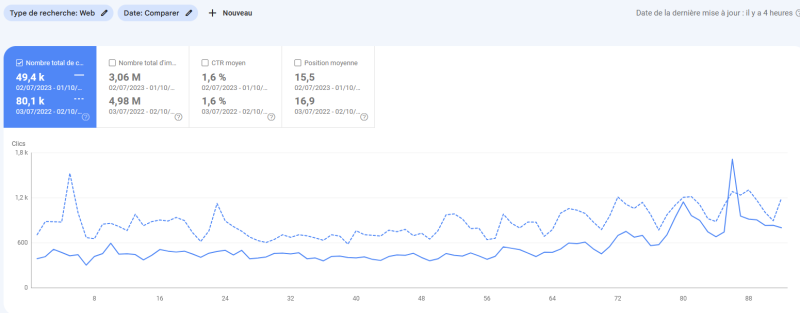
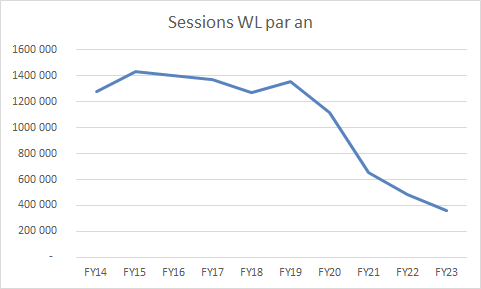
Première fois où on repasse en croissance (pour le coup, fruit de l'écriture de l'article Samuel Fitoussi, qui a super bien marché avec ses passages médias). Ca souligne le rôle du contenu dans le succès du site. Pas que des sujets techniques. Malgré tout l'amélioration semble se maintenir (le taux de décroissance diminue nettement), même si on est qu'au début (on est à environ 3,5 fois moins d'audience qu'en 2015, 2023 est extrapolé) Il va falloir continuer à optimiser pas mal de choses pour remonter.
-
Devenir du Parti Républicain Américain
Lexington a répondu à un sujet de Lexington dans Europe et international
L'establishment GOP n'a jamais été un grand fan de Trump (et Trump a déjà largement gouverné avec des random guys, par défaut). L'establishment GOP défend ce qu'ils pensent être l'intérêt du parti, donc le leur. On parle de McCarthy ici mais tu as le même sujet avec McConnell, qui, au delà du fait qu'il freeze en interview pendant une minute tous les quatre matins, est bien plus reaganien que trumpiste et joue régulièrement contre Trump. L'establishment GOP semble ne pas croire à ses chances avec Trump, mais ne dira probablement rien avant l'élection, comme ils n'avaient quasiment rien dit en 2020-2021 lors de l'invasion du Capitole et des tentatives de Trump de rester au pouvoir malgré sa défaite. Je suis assez surpris du choc frontal là perso. Si McCarthy va en frontal contre les trumpistes alors que ce n'était pas le cas en 2022, c'est probablement parce qu'il pense que se recentrer (ou ne pas encore plus se droitiser) est la meilleure voie pour gagner les élections en 2024. -
Réchauffement climatique
Lexington a répondu à un sujet de Jérôme dans Politique, droit et questions de société
Intéressant sur le discours récurrent des étatistes sur le fait que l'on aurait pas vraiment réduit le niveau de CO2 produit par unité de PIB et qu'on ne fait qu'exporter notre pollution. -
Sujet général (discussion, proposition, ...)
Lexington a répondu à un sujet de poney dans Sujets de Wikibéral
Sur notre principal concurrent, et le peu de moyens nécessaires pour y arriver https://www.liberation.fr/checknews/2017/10/23/qui-est-pierre-tourev-de-toupieorg-tres-prise-des-eleves_1652617/ -
https://x.com/williamreymond/status/1707837957435174973?s=46 Malgré ce que le tweet dit, beaucoup de débat sur qui ça peut arranger de Biden ou du futur candidat GOP. J’aurais tendance à dire que c’est bon pour Biden, mais y a de tout dans les analyses, il faudra voir ce que disent les sondages une fois le scénario présent
-
Musk, moskhos, muṣká.. Bref : la testicule de l'ère moderne
Lexington a répondu à un sujet de RaHaN dans Actualités
les chiffres de Musk étaient incohérents avec ceux de Cloudflare, on sait qui a raison désormais : les chiffres officiels de Twitter indiquent une baisse de l’audience quotidienne https://mashable.com/article/twitter-x-daily-active-users-drop-under-elon-musk -
Moins de contraintes mises à la location, type moratoire sur les sujets DPE ou que sais-je
-
J’ai quand même l’impression que la fête est finie sur le logement. La pénurie locative est devenue telle qu’ils vont devoir amplifier ce qu’ils commencent à peine sur l’assouplissement. Mais bon, j’ai toujours été un grand d’optimiste
-
TIL la tipflation et toute la remise en cause de la culture du pourboire aux US https://www.cbsnews.com/news/tipping-backlash-inflation-who-should-get-tipped/
-
Je relance d'un Sam Brinton.

-
J'essaie de visualiser Prouic chez l'esthéticienne Blague à part, ça serait intéressant de voir combien ça te fait d'augmentation du coût de la vie mais belle illustration en effet de l'intérêt d'acheter son logement
-
Je raconte my life 9 : hache de bûcheronnage et vaporetto
Lexington a répondu à un sujet de poney dans La Taverne
Vraiment top cette vidéo -
Cafouillage de comm dans la frappe sur le siège de la marine russe à Sébastopol. https://edition.cnn.com/europe/live-news/russia-ukraine-war-news-09-26-23/index.html Ca ne semble pas enlever grand chose au succès de leur frappe, mais ça fait tâche.
-
Canada, politique & sirop d'érable
Lexington a répondu à un sujet de Tramp dans Europe et international
Et ce troll en réponse 😛 -
Guerre en Ukraine : Impacts dans le reste du monde
Lexington a répondu à un sujet de Lameador dans Europe et international
J'ai du mal à voir le rapport entre une ministre et la House of Commons. Ce n'est pas elle qui a fait ovationner le gus mais le speaker de la chambre. Après, celle-ci en bonne politicienne a l'air habituée du mensonge sur ses origines, la presse canadienne l'a déjà coincée là-dessus. Mais il faudrait vraiment être très très con pour sciemment faire ovationner un criminel de guerre nazi... Surtout vu son grand père. Je n'ai toujours pas compris le motif supposé derrière tout ça. Ils avaient déjà Zelensky à la Chambre comme preuve de leur engagement, pas besoin d'inviter un criminel de guerre nazi en plus, qui plus est en connaissant "certainement" son passif comme tu l'écris. Et c'est parti, ZeroHedge est dessus. Sputnik aussi. CQFD Même Sputnik ( "fr.sputniknews.africa/20230925/le-kremlin-crie-haro-sur-laccueil-dun-ex-ss-au-parlement-canadien-1062344837.html"), citant le Kremlin, n'ose pas écrire que c'est volontaire comme invitation soit dit en passant. -
Guerre en Ukraine : Impacts dans le reste du monde
Lexington a répondu à un sujet de Lameador dans Europe et international
Ne jamais sous-estimer la connerie des politiques. Ou l'hypothèse pas forcément impossible d'un plan orchestré par certains. Après tout, vue la dite connerie, il suffit d'acheter le bon stagiaire et le tour est joué. -
Guerre en Ukraine : Impacts dans le reste du monde
Lexington a répondu à un sujet de Lameador dans Europe et international
Mon rasoir de Hanlon me dit que ça ressemble fortement à une connerie du stagiaire. Je doute fortement que ça ait été fait volontairement. Je vois par exemple que la page WP du mec date d'après l'invitation au Parlement. Et pas une seule des sources utilisées ne date d'avant le 22 septembre, ou alors ne font aucune mention de son passé waffen SS Mais putain quels cons quand même. 3. 2. 1. avant que ça soit présenté comme volontaire par RT & Sputnik -
Revenu universel, libéral-compatible ?
Lexington a répondu à un sujet de Nigel dans Philosophie, éthique et histoire
Ce n'est pas mon rôle de juger le travail de la rédac actuelle, mais effectivement, pour donner mon avis de simple lecteur, peu à l'aise avec ça -
Dans les films recevant de l'argent du CNC, tu as autant de films rentables par leur billeterie (2%) que de films faisant 0,0€ de revenus (2% aussi) Bon et surtout, 98% de films non rentables !
-
Réchauffement climatique
Lexington a répondu à un sujet de Jérôme dans Politique, droit et questions de société
Surtout, leurs conneries ça fait monter le sceptiscisme sur le réchauffement climatique. 37% des Français s'en réclament désormais. Intéressant. -
Réchauffement climatique
Lexington a répondu à un sujet de Jérôme dans Politique, droit et questions de société
J'adore le bonus "on veut pas des méchants du FN dans notre coterie hein, pas des méchants. Nous on est des gentils qui voulons de la censure. Mais des gentils." -
Réchauffement climatique
Lexington a répondu à un sujet de Jérôme dans Politique, droit et questions de société
https://fr.irefeurope.org/featured/article/bientot-une-nouvelle-loi-pour-museler-le-climatoscepticisme-dans-les-medias/ -
Guerre civile culture, IDW, SJW & co
Lexington a répondu à un sujet de 0100011 dans Politique, droit et questions de société
Non mais l'article WL est un torchon écrit à charge, qui caricature la réalité. Alors que le think tank respecte ses obligations et s'enregistre comme lobby alors qu'ils dépensent 1000€ là-dessus, ils transforment l'ifrap et Agnès Verdier Molinié en lobbyiste industrielle. C'est digne de wikirouge -
Guerre civile culture, IDW, SJW & co
Lexington a répondu à un sujet de 0100011 dans Politique, droit et questions de société
#malaise quand même